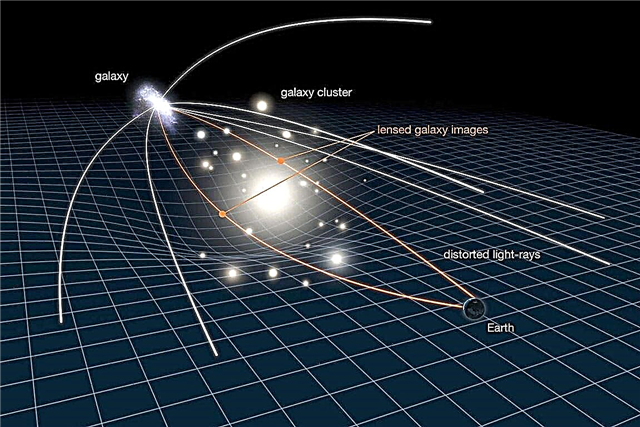
Zwaartekrachtlenzen zijn een belangrijk hulpmiddel voor astronomen die de verste objecten in het heelal willen bestuderen. Deze techniek omvat het gebruik van een enorme cluster van materie (meestal een sterrenstelsel of cluster) tussen een verre lichtbron en een waarnemer om het licht dat van die bron komt beter te zien. In een effect dat werd voorspeld door Einstein's Theory of General Relativity, kunnen astronomen objecten zien die anders misschien verduisterd zouden zijn.
Onlangs heeft een groep Europese astronomen een methode ontwikkeld om zwaartekrachtlenzen te vinden in enorme stapels gegevens. Met behulp van dezelfde kunstmatige intelligentie-algoritmen die Google, Facebook en Tesla voor hun doeleinden hebben gebruikt, konden ze 56 nieuwe kandidaten voor zwaartekrachtlenzen vinden uit een groot astronomisch onderzoek. Deze methode zou de noodzaak voor astronomen om visuele inspecties van astronomische beelden uit te voeren, kunnen elimineren.
De studie die hun onderzoek beschrijft, getiteld "Het vinden van sterke zwaartekrachtlenzen in de Kilo Degree Survey with Convolutional Neural Networks", verscheen onlangs in de Maandelijkse aankondigingen van de Royal Astronomical Society. Geleid door Carlo Enrico Petrillo van het Kapteyn Astronomical Institute, bestond het team ook uit leden van het National Institute for Astrophysics (INAF), het Argelander-Institute for Astronomy (AIfA) en de Universiteit van Napels.

Zwaartekrachtlenzen zijn handig voor astronomen, maar lastig te vinden. Normaal gesproken zou dit bestaan uit astronomen die duizenden beelden sorteren die door telescopen en observatoria zijn geknipt. Hoewel academische instellingen als nooit tevoren kunnen vertrouwen op amateurastronomen en burgerastronomen, is er geen manier om bij te blijven met miljoenen beelden die regelmatig worden vastgelegd door instrumenten over de hele wereld.
Om dit aan te pakken, wendden Dr. Petrillo en zijn collega's zich tot wat bekend staat als "Convulutional Neural Networks" (CNN), een type machine-learning algoritme dat gegevens voor specifieke patronen ontgint. Terwijl Google dezelfde neurale netwerken gebruikte om een wedstrijd van Go tegen de wereldkampioen te winnen, gebruikt Facebook ze om dingen te herkennen in afbeeldingen die op haar site zijn geplaatst, en Tesla heeft ze gebruikt om zelfrijdende auto's te ontwikkelen.
Zoals Petrillo uitlegde in een recent persartikel van de Nederlandse Onderzoekschool voor Astronomie:
“Het is voor het eerst dat een convolutioneel neuraal netwerk wordt gebruikt om bijzondere objecten te vinden in een astronomisch onderzoek. Ik denk dat het de norm zal worden, aangezien toekomstige astronomische onderzoeken een enorme hoeveelheid gegevens zullen opleveren die nodig zijn om te inspecteren. We hebben niet genoeg astronomen om dit aan te kunnen. "
Het team heeft deze neurale netwerken vervolgens toegepast op gegevens die zijn afgeleid van de Kilo-Degree Survey (KiDS). Dit project is gebaseerd op de VLT Survey Telescope (VST) van de ESO-sterrenwacht op Paranal in Chili om 1500 vierkante graden van de zuidelijke nachtelijke hemel in kaart te brengen. Deze dataset bestond uit 21.789 kleurenafbeeldingen verzameld door de VST's OmegaCAM, een multibandinstrument ontwikkeld door een consortium van Europese wetenschappers in samenwerking met de ESO.

Deze afbeeldingen bevatten allemaal voorbeelden van lichtgevende rode melkwegstelsels (LRG's), waarvan er drie bekend staan als zwaartekrachtlenzen. Aanvankelijk vond het neurale netwerk 761 kandidaten voor zwaartekrachtlenzen in dit monster. Na deze kandidaten visueel te hebben geïnspecteerd, kon het team de lijst beperken tot 56 lenzen. Deze moeten in de toekomst nog worden bevestigd door ruimtetelescopen, maar de resultaten waren vrij positief.
Zoals ze in hun onderzoek aangeven, zou zo'n neuraal netwerk, wanneer toegepast op grotere datasets, honderden of zelfs duizenden nieuwe lenzen kunnen onthullen:
“Een conservatieve schatting op basis van onze resultaten toont aan dat het met onze voorgestelde methode mogelijk zou moeten zijn om 100 massieve LRG-galaxy-lenzen te vinden bij z ~> 0,4 in KiDS wanneer ze zijn voltooid. In het meest optimistische scenario kan dit aantal aanzienlijk toenemen (tot maximaal? 2400 lenzen), wanneer de selectie van kleurmagneten wordt verbreed en CNN wordt opgeleid om kleinere lenzen met beeldscheidingslens te herkennen. ”
Bovendien herontdekte het neurale netwerk twee van de bekende lenzen in de dataset, maar miste de derde. Dit was echter te wijten aan het feit dat deze lens bijzonder klein was en dat het neurale netwerk niet was opgeleid om lenzen van dit formaat te detecteren. In de toekomst hopen de onderzoekers dit te corrigeren door hun neurale netwerk te trainen om kleinere lenzen op te merken en valse positieven af te wijzen.
Maar natuurlijk is het uiteindelijke doel hier om de behoefte aan visuele inspectie volledig te verwijderen. Door dit te doen, zouden astronomen geen gruntwerk meer hoeven te doen en zouden ze meer tijd kunnen besteden aan het ontdekkingsproces. Op vrijwel dezelfde manier zouden machine learning-algoritmen kunnen worden gebruikt om astronomische gegevens te doorzoeken op signalen van zwaartekrachtgolven en exoplaneten.
Net zoals andere industrieën terabytes van consumenten of andere soorten "big data" proberen te begrijpen, zou het veld astrofysica en kosmologie kunnen gaan vertrouwen op kunstmatige intelligentie om de patronen in een universum van onbewerkte gegevens te vinden. En de uitbetaling is waarschijnlijk niets minder dan een versneld ontdekkingsproces.